public
Updated 4/30/2019
Install and Configure Spark on My Windows 10
I’v installed Anaconda Python, with PySpark and Findspark modules. I always use my “main” virtual env to do everything. I left my “base” alone. See my other page for details.
I’ve read many Spark Installation Guide for Windows. I always wonder why winutils (Window version of hadoop) is needed (for a standalone spark), until saw following post:
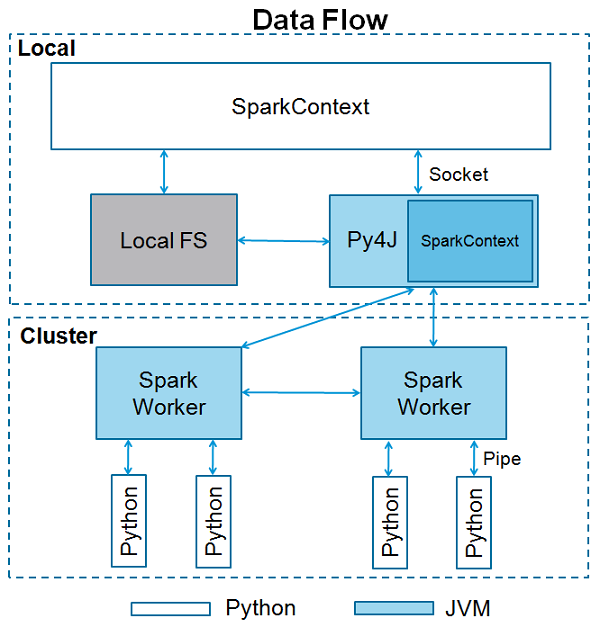
Working on apache spark on windows
.... Even if you don't use Hadoop, Windows needs Hadoop to initialize the "hive" context. You get the following error if Hadoop is not installed. ....
1. Install java
I installed jdk1.8.0_181 64-bit in C:\Java\jdk1.8.0_181, and I noticed there are a few other JAVA versions existed on my box.
In system environment, I setup JAVA_HOME to “C:\Java\jdk1.8.0_181”, and set PATH to C:\Java\jdk1.8.0_181\bin. I also I also set
Below is in system environment
JAVA_HOME=C:\Java\jdk1.8.0_181
_JAVA_OPTIONS=-Xmx16G -Xms512M
I noticed when I launch java I received following error
C:\Users\xxxx>java -version
Picked up _JAVA_OPTIONS: -Xmx16G -Xms512M
Invalid maximum heap size: -Xmx16G
The specified size exceeds the maximum representable size.
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
This is because the java in PATH (set before this version) was 32-bit java, which can’t utilized 16G stack
Note: setting Xmx16G in system evironment applies to all JVM. So it breaks some of my applications which uses 32bit Java. Need to find another place for Spark.
2. Install Spark
I downloaded spark2.4.2 “Pre-built for Apache Hadoop 2.7 and later” tgz file. tar xvf to ~\Programs\spark-2.4.2-bin-hadoop2.7
Below is in system environment
SPARK_HOME=C:\Users\xxxx\Programs\spark-2.4.2-bin-hadoop2.7
3. Install winutils.exe
I downloaded winutils.exe and put it in %SPARK_HOME%\hadoop\bin
Below is in system environment
HADOOP_HOME=%SPARK_HOME%\hadoop
and add path to
%HADOOP_HOME%\bin
4. Test
I tested following code in VS Studio
#%%
import findspark
findspark.init()
#%%
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.sql ("select 'spark' as hello ")
df.show()
#%%
df = spark.read.csv("a.csv",header=True, inferSchema=True)
df.show()
df.count()
5. Spark environment
I can launch pyspark shell (in git shell so I have python interpreter setup in path) as
~/Programs/spark-2.4.2-bin-hadoop2.7/bin/pypark2.cmd
then I can access Spark job status at
http://127.0.0.1:4040/jobs/
I ran the python code in the pyspark shell
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.sql ("select 'spark' as hello ")
df.show()
The job show in web gui
6. How to monitor job submitted by Jupyter/VS Code?
I tried http://127.0.0.1:4041/jobs/ which worked - it display all the jobs I submitted via VS Code.
7. Oracle JDBC Test
Edit spark-defaults.conf file (copied from spark-defaults.conf.template) in SPARK_HOME/conf
Add following line:
spark.driver.extraClassPath c:\\Users\\xxxx\\Programs\\sqldeveloper\\jdbc\\lib\\ojdbc8.jar
Here I used the JDBC came with SQL Developer. The configuration was tested with following code
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
empDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:@//hostname:port/sid") \
.option("dbtable", "TEST_TABLE") \
.option("user", "secret_uid") \
.option("password", "secret_pwd") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()
empDF.count()
Learning Materials
[The Internal of Spark SQL] (https://jaceklaskowski.gitbooks.io/mastering-spark-sql/)